The Enterprise Site Architecture Audit Checklist: Finding $100K+ in Lost Organic Revenue Hidden in Your Information Structure

Enterprise site architecture audits recover organic revenue by exposing how a site’s URL hierarchy, internal link graph, and crawl directives misroute search engine attention away from commercial pages. The common misunderstanding: teams treat architecture work as technical cleanup when the real mechanism is revenue-path alignment across three structural layers.
TL;DR: An enterprise site’s URL hierarchy, internal link topology, and crawl directives determine which pages Google discovers, which accumulate authority, and which rank for commercial queries. When structure drifts from revenue intent through years of redesigns and content sprawl, the result is organic traffic landing everywhere except the pages that generate pipeline. Architecture audits trace that misalignment layer by layer.
How Information Hierarchy Dictates Crawl Allocation
Google’s own documentation states that crawl budget management matters most for “large sites with thousands of URLs” and sites where “a large portion of pages are duplicated or low quality.” For enterprise sites running 50,000+ URLs across multiple subdomains, product lines, and regional variations, the hierarchy you’ve built directly controls how Googlebot spends its finite crawl cycles.
The mechanism works like this: Googlebot enters through your highest-authority pages (typically your homepage and a handful of category pages with strong backlink profiles). It follows internal links outward. The depth, density, and directionality of those links determine which URLs get discovered, how frequently they get recrawled, and whether they enter Google’s index at all.
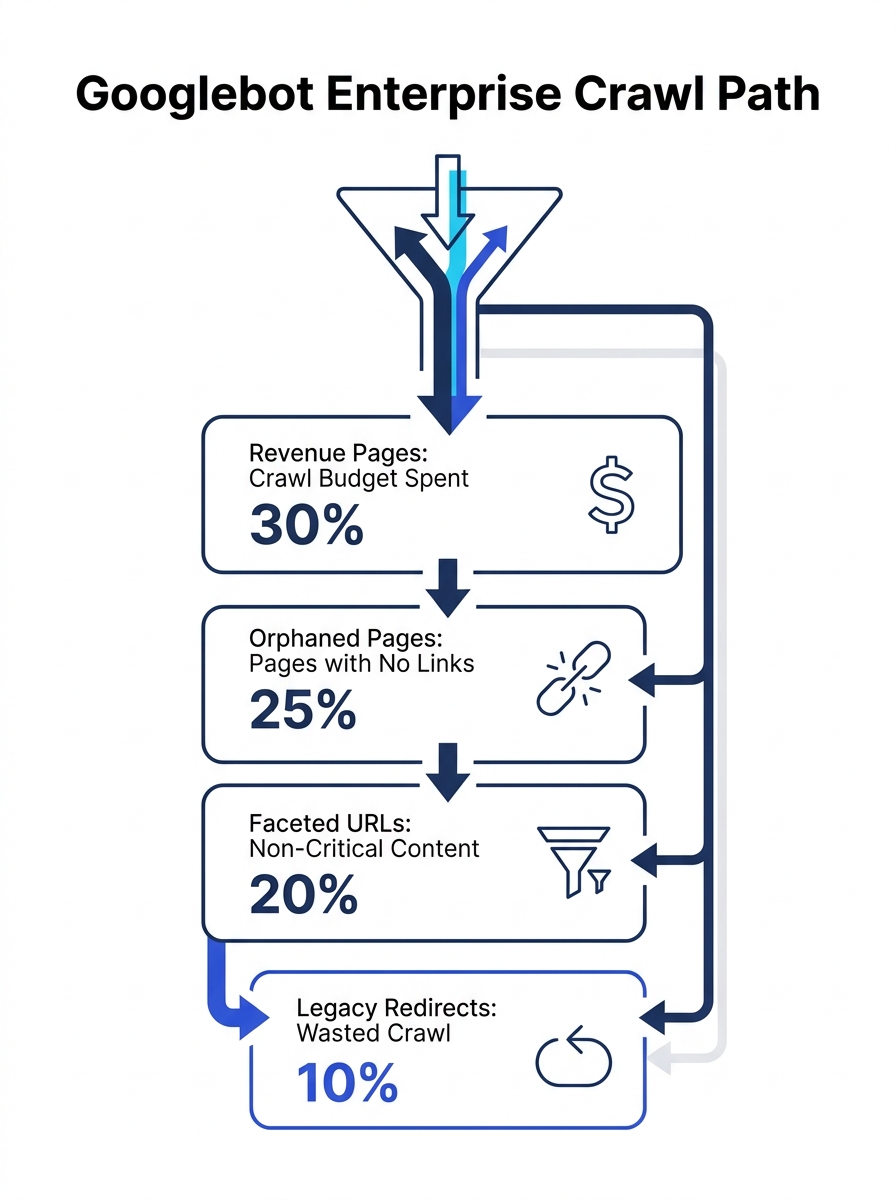
When an enterprise site has accumulated layers of enterprise SEO technical debt through orphaned landing pages from past campaigns, expired product categories still generating faceted URLs, and staging subdomains accidentally left open to crawlers, Googlebot burns crawl budget on URLs that produce zero revenue. Enterprise sites running crawl budget optimization at scale routinely discover that 30-40% of their indexed URLs contribute nothing to organic sessions. We’ve detailed how this crawl waste compounds in our breakdown of how enterprise sites leak SEO value through architecture debt.
The crawl budget optimization checklist for an enterprise site starts here, at the allocation layer. But most teams stop here too, which is why their audits produce cleanup reports instead of revenue recovery plans.
Template-Level Errors and the Multiplication Effect
A single misplaced canonical tag on a page template that controls 12,000 product pages creates 12,000 canonicalization errors simultaneously. This multiplication effect is what separates enterprise architecture audits from SMB site reviews.
As one enterprise SEO resource explains: “For enterprise sites, technical SEO issues at the template level affect thousands or millions of pages simultaneously, which means identifying and fixing template-level problems produces outsized returns compared to page-by-page remediation.”
The common template-level architecture failures fall into predictable patterns:
- Pagination directives that create infinite crawl loops across faceted navigation (common in ecommerce and real estate portals with filter combinations generating tens of thousands of parameter-based URLs)
- Hreflang implementation errors on multi-regional templates that cause Google to index the wrong country variant for a given query
- JavaScript rendering dependencies where critical navigation links only exist inside client-rendered components, making them invisible to Googlebot’s initial HTML pass
- Canonical chains where Page A canonicalizes to Page B, which canonicalizes to Page C, diluting the signal until Google ignores all three
The Over The Top SEO team’s 47-point enterprise audit framework specifically flags template-level analysis across “crawlability, indexability, site speed, Core Web Vitals, mobile optimization, and JavaScript rendering” as the foundation layer. Fix one template, fix thousands of pages. Miss one template error, and thousands of pages silently drop from the index.
This is why an enterprise site architecture SEO audit produces returns that page-level optimizations never match. The scale works in your favor when you find the right template problems.
Authority Flow: Where Link Equity Gets Lost in the Plumbing
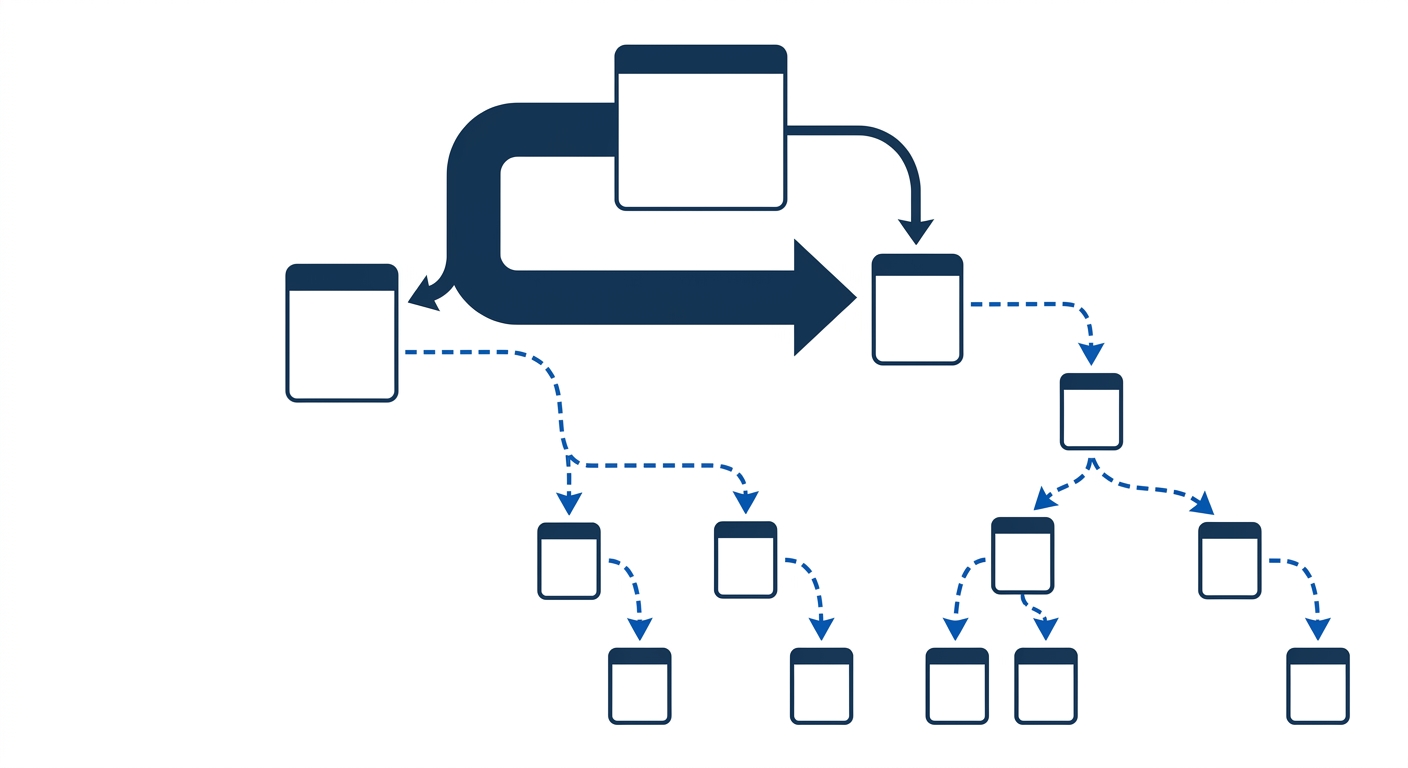
How a site is structured determines how search engine crawlers navigate it and how link equity flows from high-authority pages to the pages that need it.
That principle, repeated across every credible enterprise SEO audit resource, captures the second layer of the mechanism. Your site earns authority through backlinks, brand mentions, and topical relevance signals. But that authority doesn’t distribute evenly across every URL. It flows through internal links, following the paths your architecture defines.
The problem in most enterprise sites: authority concentrates at the top of the hierarchy (homepage, main category pages, blog index) and dissipates before reaching the pages that actually convert visitors into leads or sales. Product detail pages, service pages, location-specific landing pages sit four, five, or six clicks deep. By the time link equity trickles down to them, the signal is too weak to compete for commercial queries.
An effective architecture audit maps this flow explicitly. You’re looking at internal link distribution, click depth from the homepage, and the ratio of internal links pointing to commercial pages versus informational content. Enterprise audit practitioners recommend validating XML sitemaps, robots.txt rules, and crawl-index efficiency as baseline checks, but the authority flow analysis is where the revenue insight lives.
We’ve written extensively about how internal linking compounds SEO growth in enterprise contexts. The key insight for marketing leaders evaluating an agency’s audit deliverable: if the report doesn’t include a link equity distribution analysis showing where authority pools and where it starves, the audit is incomplete.
The Revenue-Intent Mismatch Layer
The third and most commercially significant layer of the mechanism is what we call the Revenue-Intent Mismatch: the gap between the pages your site architecture prioritizes for search engines and the pages your business needs ranking for commercial queries.
This mismatch develops gradually. A company launches with a clean architecture where product and service pages sit high in the hierarchy. Over three to five years, content marketing adds hundreds of blog posts. Regional expansions add location pages. Campaign teams spin up microsites and landing pages. The CMS accumulates URL patterns from two or three redesigns. Eventually, the informational content outnumbers commercial pages ten to one, and Google’s crawl allocation follows that ratio.
Search Engine Land reported that some sectors have seen organic traffic drop 15% to 64% since AI Overviews launched. Semrush research analyzing over 10 million keywords found that 88.1% of queries triggering AI Overviews are informational in nature. When your architecture funnels most of Google’s attention toward informational pages that AI Overviews are already cannibalizing, the revenue loss compounds in two directions: commercial pages don’t rank because they’re structurally starved, and informational pages that do rank generate declining click-through rates.
This is the mechanism through which information architecture shapes organic growth or erodes it. The audit’s job is to quantify the mismatch and map the structural changes needed to redirect crawl priority and authority flow toward pages with commercial intent.
For brands already seeing the effects of AI-driven search shifts, our analysis of how site structure multiplies organic growth covers the compounding dynamics in detail. And understanding how Generative Engine Optimization fits into an architecture strategy helps ensure the structural fixes account for how AI retrieval systems prioritize content alongside traditional rankings.
What a Business Impact Score Actually Measures
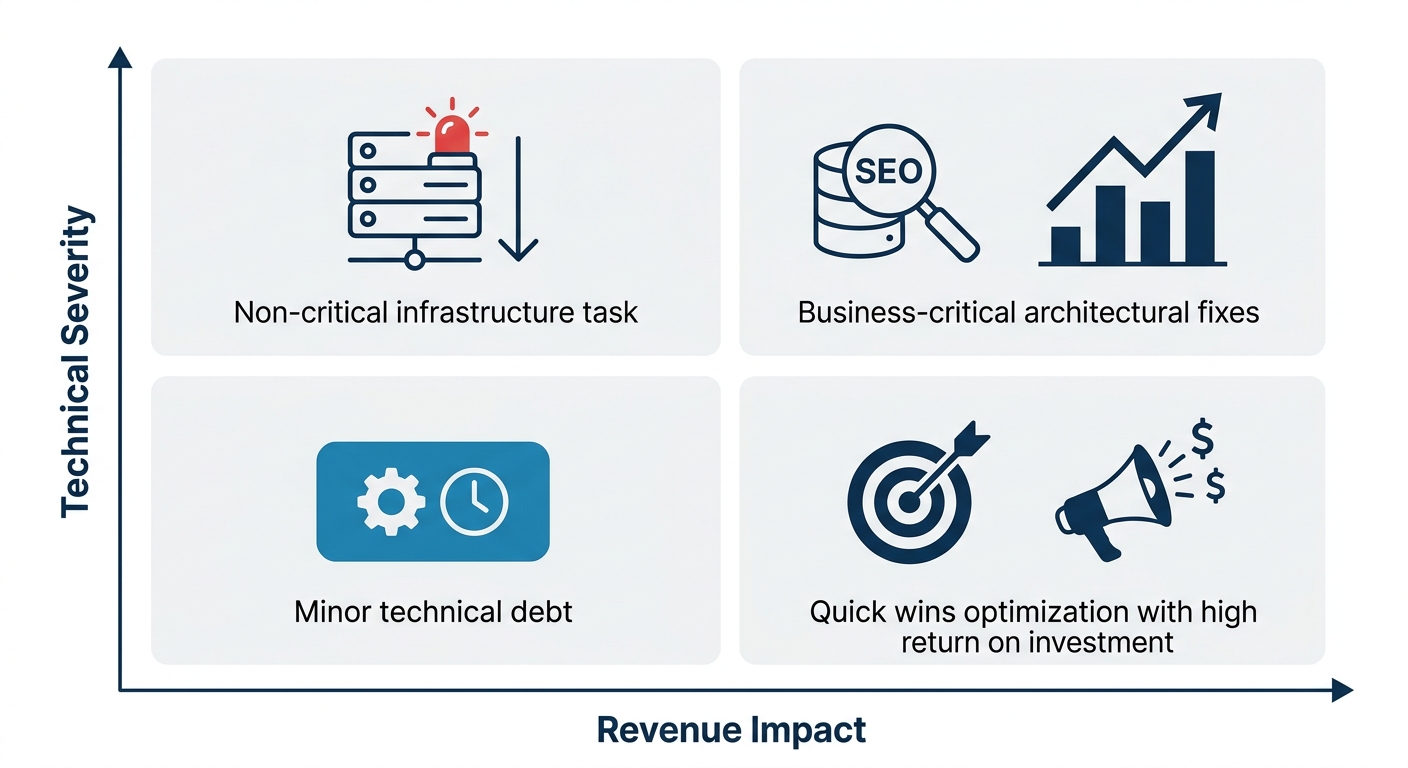
The mechanism that separates a useful enterprise architecture audit from a spreadsheet of crawl errors is business impact scoring. Standard audit tools flag issues by technical severity: a 5xx server error is “critical,” a missing alt tag is “low.” This classification tells you nothing about revenue impact.
Business impact scoring connects each architectural issue to three variables:
- Affected URL count: how many pages does this template-level or structural issue touch?
- Organic traffic potential of affected pages: what’s the estimated search volume for queries these pages target?
- Commercial intent alignment: are the affected pages tied to revenue-generating actions (purchases, lead forms, demo requests), or are they informational assets?
An issue affecting 200 blog posts with informational queries scores differently than an issue affecting 50 product category pages targeting high-commercial-intent keywords, even if the technical severity is identical. Enterprise SEO resources note that technical debt can result in lost revenue, increased costs, and the inability to address growing market needs, but without business impact scoring, teams have no way to prioritize which debt to pay down first.
| Scoring Variable | What It Captures | Why It Matters for Prioritization |
|---|---|---|
| Affected URL count | Scale of the template or structural issue | Determines whether a fix touches 50 pages or 50,000 |
| Organic traffic potential | Search volume and current ranking position of affected URLs | Separates high-opportunity pages from low-demand URLs |
| Commercial intent alignment | Whether affected pages serve conversion goals | Prevents teams from prioritizing blog fixes over product page recovery |
Our walkthrough of diagnosing and prioritizing SEO fixes that recover organic revenue covers the prioritization workflow in more depth. The point here is mechanical: the audit’s value comes from the scoring model applied to the findings, not from the findings alone.
Governance Failures That Regenerate Technical Debt
Even after architectural fixes ship, enterprise sites face a structural problem that smaller sites don’t: governance. Multiple teams make changes daily. Without governance protocols, the architecture debt you cleared in Q1 regenerates by Q3.
Warning: The most common governance gap we see: no approval flow for robots.txt modifications. A single engineering change to crawl directives can de-index an entire product directory overnight, and without a change log, the root cause takes weeks to identify.
The governance layer of the mechanism includes:
- Robots.txt change logs with required approval flows before any crawl directive modification goes live
- URL creation policies that enforce naming conventions, canonical declarations, and sitemap inclusion for every new page type
- Template change review requiring SEO impact assessment before any CMS template modification deploys to production
- Redirect expiration audits on a quarterly cycle to prevent 301 chain accumulation
CMOs managing multi-location brands know this governance challenge well. Our coverage of infrastructure gaps blocking ROI measurement in multi-location contexts illustrates how the same structural fragmentation plays out across regional sites. The audit identifies the current state; governance prevents the drift from recurring.
Where the Model Breaks
This three-layer model works well for sites where organic search is a primary acquisition channel and the URL count is large enough for structural decisions to materially affect crawl behavior. It breaks in specific scenarios.
Sites under 5,000 URLs rarely have genuine crawl budget constraints. Google will crawl everything regardless of architectural inefficiency. The authority flow and intent alignment layers still apply, but the crawl allocation analysis delivers minimal insight at this scale.
Single-product SaaS companies with lean site architectures face different organic challenges, typically content authority and topical coverage rather than structural misrouting. An architecture audit will confirm the structure is sound, but the revenue opportunity lives in content strategy, not URL hierarchy.
Post-migration sites present a hybrid problem. The architecture audit framework applies, but the findings interleave with migration-specific issues (redirect mapping gaps, domain authority consolidation delays, staging environment bleed) that require a different diagnostic sequence. We’ve covered the post-migration traffic plateau phenomenon separately because the remediation path diverges from a standard architecture audit.
The model also assumes your analytics infrastructure can attribute organic revenue to specific page groups. If your attribution setup can’t distinguish between organic sessions landing on commercial pages versus informational pages, the business impact scoring layer loses its precision. You can still run the audit, but the prioritization becomes directionally correct rather than quantitatively precise.
Architecture audits are a mechanism for recovering revenue that’s structurally trapped inside enterprise sites large enough for structural decisions to compound across thousands of pages. They fail when the site is too small for structure to matter, when the organic channel isn’t a material revenue contributor, or when the attribution layer can’t connect structure to business outcomes. Knowing which scenario you’re in before commissioning the audit is the first decision that actually matters.








