The Crawl Budget Hemorrhage: Why Enterprise Sites Leak 60% of SEO Value Through Hidden Architecture Debt

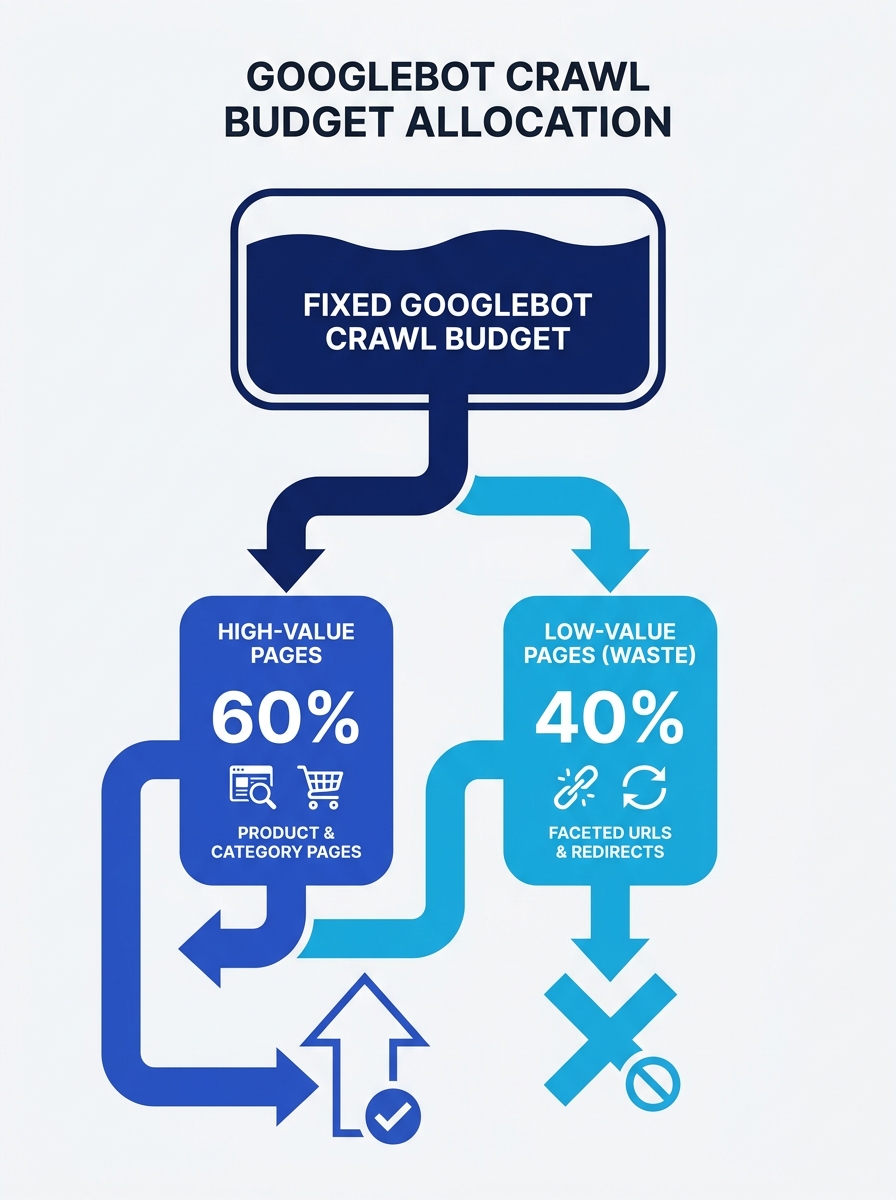
Googlebot allocates a fixed crawl budget per hostname. When an enterprise site carries thousands of faceted URLs, expired product pages, and chained redirects, the crawler spends its allotment on pages that produce zero organic value. Revenue-driving URLs sit in the “Discovered – currently not indexed” queue for weeks while the bot processes dead weight.
TL;DR: Crawl budget waste on enterprise sites stems from five structural sources: uncontrolled URL parameters, JavaScript rendering overhead, redirect chains, orphaned pages, and poorly segmented sitemaps. Fixing them requires changes to publishing workflows, engineering standards, and information architecture governance, not a one-time cleanup.
How Googlebot Allocates Crawl Budget
Google assigns each hostname two constraints: a crawl rate limit based on server responsiveness, and a crawl demand score based on perceived freshness and importance. According to Google’s crawl budget documentation, the system won’t shift freed-up budget from robots.txt-blocked pages to other URLs. Blocking low-value pages doesn’t automatically redirect crawler attention to high-value ones.
For sites under roughly 10,000 URLs, crawl budget rarely matters. Google will get to everything. But enterprise sites routinely manage 100,000 to several million URLs. At that scale, every URL the crawler visits has an opportunity cost. When Googlebot spends 40% of its requests on parameterized pages returning near-duplicate content, it processes fewer category pages, product detail pages, and editorial URLs that actually rank and convert.
The core mechanism works like a fixed daily bank account. The site can’t increase the deposit, but it controls where the money goes. Architecture debt is the equivalent of automatic withdrawals for subscriptions you canceled three years ago.
ALM Corp’s technical framework for enterprise crawl optimization describes crawl budget optimization as “a quality-control system for discoverability.” That framing is precise. This isn’t a performance tuning exercise. It’s a system for controlling which URLs represent your site in search results and which ones waste the crawler’s finite attention.
Faceted URLs Are the Biggest Single Drain
Faceted navigation generates unique URLs for every combination of filter, sort order, and pagination state. An ecommerce site with 50 product categories, 8 filter types, and 3 sort options can produce over 1,200 unique URL patterns per category. Multiply across the full catalog and the crawlable URL space balloons into the millions. Most of these pages serve identical or near-identical content.
Go Fish Digital’s 2026 analysis of enterprise ecommerce crawl budgets recommends a “zero-waste architecture” built on governing facets and URL states, segmenting sitemaps, and improving crawl-to-index alignment. The fix involves choosing which facets get indexable URLs (typically high-search-volume filters like brand or material type) and rendering all others through JavaScript state changes that produce no crawlable URL.
Canonical tags help with duplicate content signals, but they don’t stop the crawler from requesting the page. Google’s documentation confirms that the bot still fetches canonical-tagged pages before processing the tag. So 500 faceted URLs pointing canonical to a single category page still consume 500 crawl requests.
This is where information architecture technical debt becomes most expensive. The faceted navigation system was usually built to serve users with no SEO input on which URL patterns should exist. Retrofitting controls years later means auditing every filter combination against search demand data. That’s the kind of cross-team project that stalls in enterprise organizations for quarters. The link between site architecture decisions and organic revenue is direct, even when the lag between cause and effect makes it hard to spot in quarterly reporting.
How JavaScript Rendering Multiplies the Cost
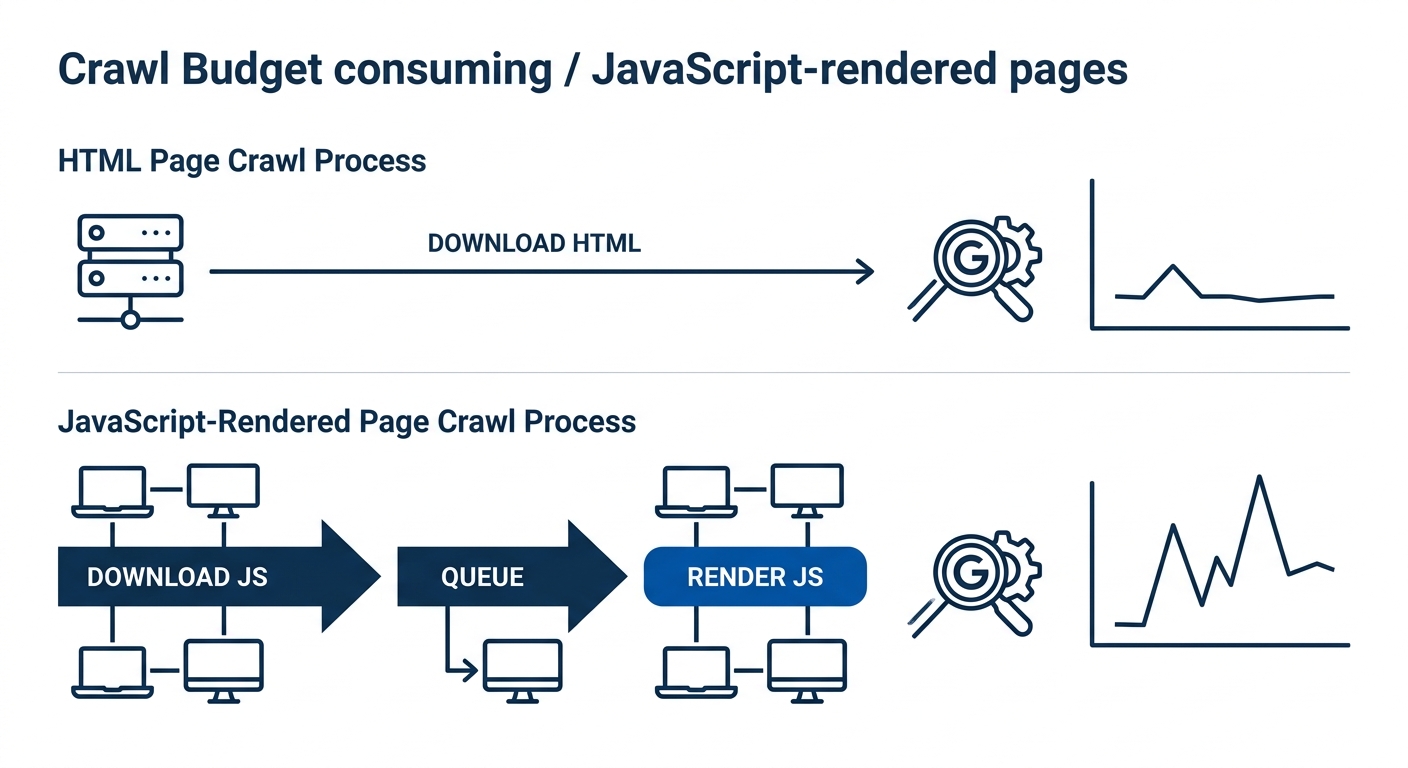
JavaScript-heavy pages cost more crawl budget because Googlebot processes them in two passes. First it downloads the HTML shell. Then it queues the page for rendering in a separate system using a headless Chromium instance. According to analysis from Prerender.io, rendering JavaScript requires approximately 9 times more resources than processing standard HTML.
That 9x multiplier means a single JS-rendered page eats the crawl budget equivalent of 9 static pages. For an enterprise site with 200,000 JavaScript-dependent product pages, the effective crawl capacity drops to roughly 22,000 pages in a standard HTML environment.
Sites with over 10,000 frequently updated pages often solve this with prerendering services that generate static HTML snapshots for crawlers. The prerendered version serves the bot what it needs on the first request, eliminating the rendering queue entirely. One mid-sized retailer documented a 62% reduction in First Contentful Paint after optimizing its critical rendering path, consolidating 5 redundant JavaScript libraries into 1 package, and saving 3.8MB per page load through proper image sizing and WebP conversion.
Warning: If your engineering team built the site on React, Next.js, Vue, or Angular, ask whether server-side rendering or prerendering is in place for Googlebot specifically. If the answer is “we rely on client-side rendering” or “we haven’t addressed it,” you’ve found one of your organic growth scaling bottlenecks.
Redirect Chains Compound the Problem Silently
A single 301 redirect burns two crawl requests instead of one. The bot requests the original URL, receives the redirect response, then requests the destination. Chain 3 or 4 redirects together (common after multiple site migrations) and a single page consumes 4 to 5 requests. Google has stated that chains longer than 5 hops may simply be abandoned, meaning the destination page never gets crawled at all.
Enterprise sites accumulate redirect chains the same way old houses accumulate paint layers. Each redesign or platform migration adds a new redirect mapping on top of the previous one. After 3 migrations over a decade, it’s common to find redirect chains 4 to 6 hops deep on 15% to 20% of the site’s historical URL inventory. We’ve written about how domain transitions create post-migration traffic plateaus specifically because this redirect debt goes undiagnosed for months.
Orphaned pages compound the problem from the other direction. These are URLs that exist in the site’s database and XML sitemaps but receive no internal links from any other page. Googlebot still discovers them through the sitemap, crawls them, and tries to index them. But without internal link signals, they rank poorly or not at all. The crawl requests are wasted. A structured approach to auditing non-revenue URLs draining organic visibility can expose these pages and quantify their crawl cost.
Crawl budget waste on enterprise sites is a workflow problem disguised as a technical one. Every ungoverned URL published without architectural review adds to the debt.
Why Sitemap Segmentation Changes the Equation
A single monolithic sitemap containing every URL tells Googlebot nothing about priority. Segmented sitemaps, split by content type (products, categories, editorial, location pages), give the crawler structural signals about the site’s architecture. They also give SEO teams diagnostic power. Google Search Console reports crawl and index data per sitemap. Segmented files make it possible to see that 92% of product pages are indexed while only 34% of blog posts are, then investigate why.
Segmentation pairs with lastmod timestamps. When lastmod values are accurate, reflecting actual content changes rather than template updates, they tell Googlebot which pages have genuinely changed. Inaccurate timestamps erode Googlebot’s trust in the sitemap signal over time, causing the bot to fall back on its own crawl patterns. Those patterns tend to favor high-authority pages and neglect deeper ones.
For multi-country or multi-language enterprise sites, complexity increases further. Each subdirectory or subdomain develops different crawl behavior. Hreflang errors and duplicated translation templates create additional crawl waste. A site serving 12 markets with 12 language subdirectories asks Googlebot to manage 12 partially overlapping URL inventories. Each one carries its own faceted navigation sprawl, redirect debt, and orphaned page problems.
Building the right information architecture that compounds organic growth requires treating sitemaps as a first-class engineering deliverable. And when the front end itself needs restructuring, working with a web design agency that understands enterprise site architecture SEO prevents introducing new crawl debt during the rebuild. The internal linking architecture of the rebuilt site needs to be specified before design begins, not bolted on after launch.
Publishing Workflows Feed the Debt Cycle
Content publishing at scale requires coordination among writers, editors, designers, and developers. Analysis of enterprise SEO bottlenecks shows that publishing processes with excessive approval layers can delay even simple blog updates by several weeks. That delay creates a secondary crawl budget problem. By the time pages go live, the content may address search patterns that have already shifted.
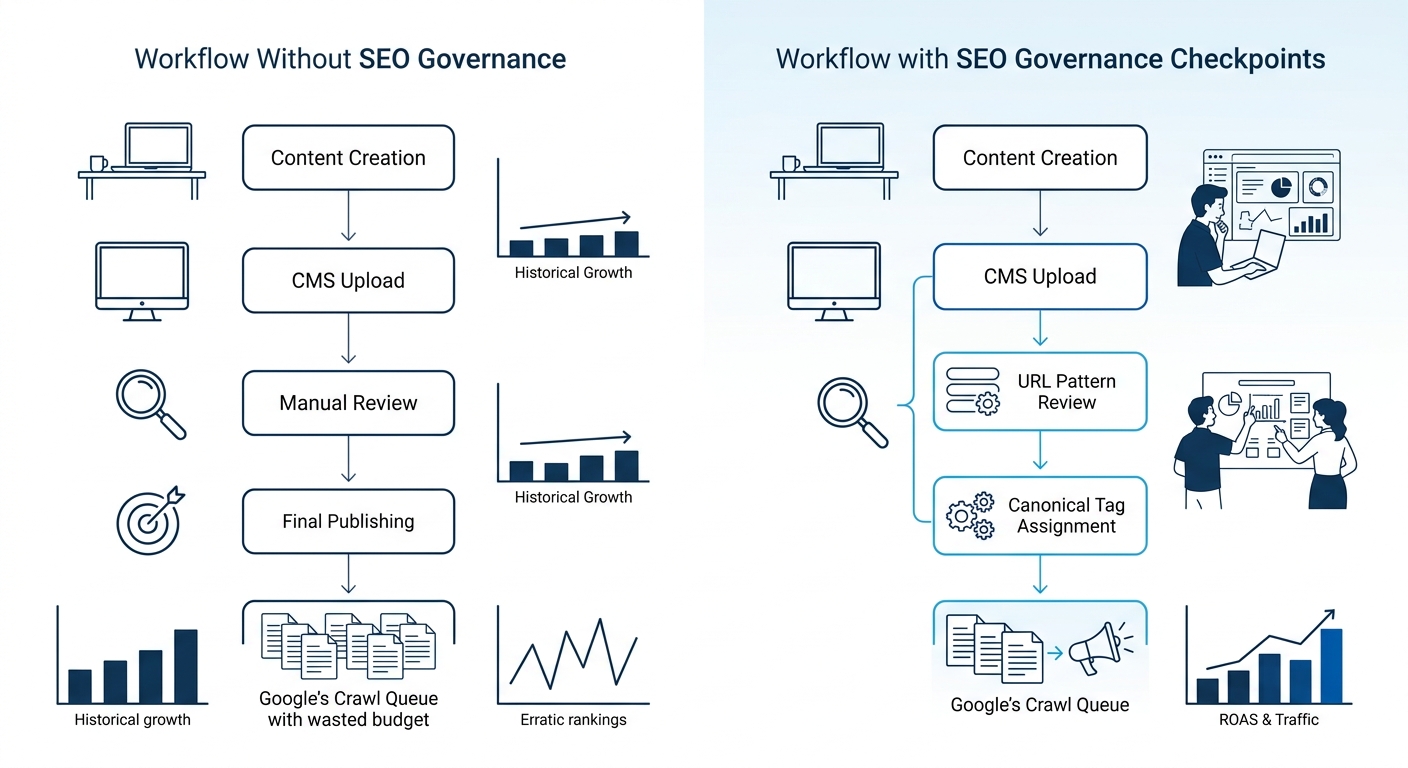
But the bigger issue is governance. Most enterprise publishing workflows have no SEO checkpoint. Pages go live without anyone verifying that URL structure follows the site’s taxonomy, that canonical tags point to the correct parent, or that internal links connect new content to the existing topic architecture. Each ungoverned page is a small addition to the site’s information architecture technical debt. Over 200 to 400 pages per quarter, the debt accumulates into measurable drag on crawl efficiency.
The fix is procedural. It means embedding URL pattern validation, canonical assignment, and internal linking into the CMS publishing flow so those decisions happen before the page enters Google’s crawl queue. Organizations that skip this step see their crawl-to-index ratio decline steadily over 12 to 18 months, even when content quality stays high. The SEO debugging framework we’ve documented helps diagnose where in the crawl-to-ranking pipeline the breakdown actually occurs.
Where the Model Breaks
The mechanism above has clear limits. Crawl budget optimization ensures Googlebot finds and indexes pages efficiently. It cannot fix poor content quality, weak backlink profiles, or misaligned search intent. A perfectly crawled page targeting the wrong query still won’t rank.
The model also breaks when organizational politics override technical recommendations. Blocking 400,000 faceted URLs requires buy-in from product, engineering, and UX teams. Collapsing redirect chains after a migration demands engineering hours that compete with feature development sprints. Retiring orphaned pages means someone has to decide what to delete, which in many enterprise organizations triggers a months-long stakeholder review.
And there’s a measurement lag that tests patience. Crawl budget improvements show up in log file data within days. But visible changes in indexed page counts, ranking positions, and organic traffic take 4 to 12 weeks. Marketing leaders expecting immediate results from a crawl audit will be waiting. The payoff is real and, for large sites, substantial. It arrives on Google’s timeline, though, and no amount of internal urgency changes that cadence. The organizations that sustain gains are the ones that treat crawl efficiency as an ongoing operational concern, with the same quarterly review rhythm they apply to site uptime or page load performance.