JSON-LD vs Microdata: Which Schema Format Actually Wins in 2026
The 2011 Launch: Microdata Was the Default
Schema.org went live on June 2, 2011, jointly backed by Google, Bing, Yahoo, and Yandex. Its original documentation used Microdata as the primary encoding format, and that choice shaped how an entire generation of developers thought about structured data.
The logic made sense at the time. Microdata wove structured data directly into HTML elements using attributes like itemscope, itemtype, and itemprop. If you had a product listing on the page, you tagged the product name, price, and availability right inside the same HTML that rendered those details to the visitor. The structured data and the visible content lived in the same place.
For developers building relatively simple pages — a local business address, a recipe, a basic product card — Microdata worked well enough. The format kept things honest: whatever you told Google had to match what appeared on screen because the markup was the content.
But complexity grew fast. E-commerce sites needed Product, Offer, AggregateRating, and Breadcrumb schemas on a single page. Real estate listings required nested Organization → Agent → Property relationships. Microdata’s inline nature turned those pages into tangles of attributes that were painful to debug and fragile to maintain.

Google Picks a Side
By 2015, JSON-LD had emerged as an alternative encoding for Schema.org vocabulary. Instead of scattering attributes throughout your HTML, you dropped a single script block — typically in the head or at the end of the body — containing a clean JSON object that described the page’s entities and their relationships.
Google’s developer documentation began recommending JSON-LD as the preferred format. The reasoning was practical: JSON-LD doesn’t touch your visible markup. A front-end redesign won’t accidentally break your structured data. A CMS migration won’t strip out itemprop attributes that were embedded in templates three developers ago.
As Google’s structured data documentation states, sites shouldn’t “add structured data about information that is not visible to the user, even if the information is accurate.” That rule applies equally to both formats. But JSON-LD made compliance easier because it separated concerns. Content teams handled the page, SEO teams handled the schema, and neither group accidentally broke the other’s work.
If you’ve ever tried to debug product page schema on an e-commerce site, you know the pain. Microdata errors tend to cascade: one missing closing tag or misplaced itemprop attribute throws off every subsequent entity on the page. JSON-LD errors, by contrast, stay contained within the script block. You fix the JSON, and nothing else on the page changes.
The Adoption Numbers Diverge
The Web Data Commons project, which tracks structured data usage across the Common Crawl dataset, documented a clear inflection point. Between 2019 and 2021, Microdata usage peaked and then began declining in 2022 and 2023. JSON-LD, meanwhile, showed exceptional growth starting in 2020 and continued climbing through subsequent years. By 2024, JSON-LD had been adopted by over 308,000 pay-level domains tracked in that dataset.
The Schema.org project itself notes that as of 2024, over 45 million web domains use Schema.org vocabulary, generating more than 450 billion structured data objects. The bulk of that growth has been driven by JSON-LD adoption.
Three forces converged to drive the shift:
- CMS plugin ecosystems matured. WordPress plugins like Yoast, Rank Math, and Schema Pro all default to JSON-LD output. Shopify generates JSON-LD for product and breadcrumb schemas automatically. When the tools default to one format, adoption follows.
- JavaScript frameworks took over. React, Vue, and Angular-based sites render content dynamically. Injecting Microdata attributes into server-rendered HTML is straightforward, but managing them in component-based architectures where the DOM is assembled client-side is messy. JSON-LD works as a separate data layer, making it a natural fit for modern front-end stacks.
- Testing tools aligned. Google’s Rich Results Test and Schema Markup Validator both parse JSON-LD cleanly. The feedback loop of writing JSON-LD, testing it, fixing errors, and retesting became significantly faster than doing the same with inline Microdata.
When AI Search Entered the Picture
The rise of AI Overviews in Google Search, along with answers from Copilot, Perplexity, and other LLM-powered tools, added a new variable to the structured data 2026 conversation. Generative Engine Optimization (GEO) became a real consideration for brands that wanted their content cited in AI-generated answers.
For Philippine businesses adapting to how AI is reshaping local search, the practical question became: do AI crawlers actually read structured data, and does the format matter?
The answer is nuanced. Google’s own systems — the ones powering AI Overviews — process JSON-LD at scale. They use it to validate facts, extract entities, and generate citations. As Incremys noted in their 2026 analysis, “generative systems (LLMs) tend to favour information that is explicit, consistent and straightforward to extract.” JSON-LD schema markup fits that description well because it presents entities and relationships in a clean, parseable format without the noise of surrounding HTML.
Some independent tests have shown mixed results with third-party AI tools. A test conducted in August 2025 suggested that certain AI agents strip out script blocks to reduce context load during live queries. But this distinction matters less than it sounds: the structured data still gets ingested during training and indexing. And Google’s systems, where the overwhelming majority of search traffic originates, handle JSON-LD without issues.
JSON-LD’s real advantage in the AI era is the same advantage it had before AI: separation of concerns makes the data easier to maintain, audit, and scale.
Microdata Still Has Defenders (And Some Valid Points)
Dismissing Microdata entirely would be wrong. The format has genuine strengths in specific situations.
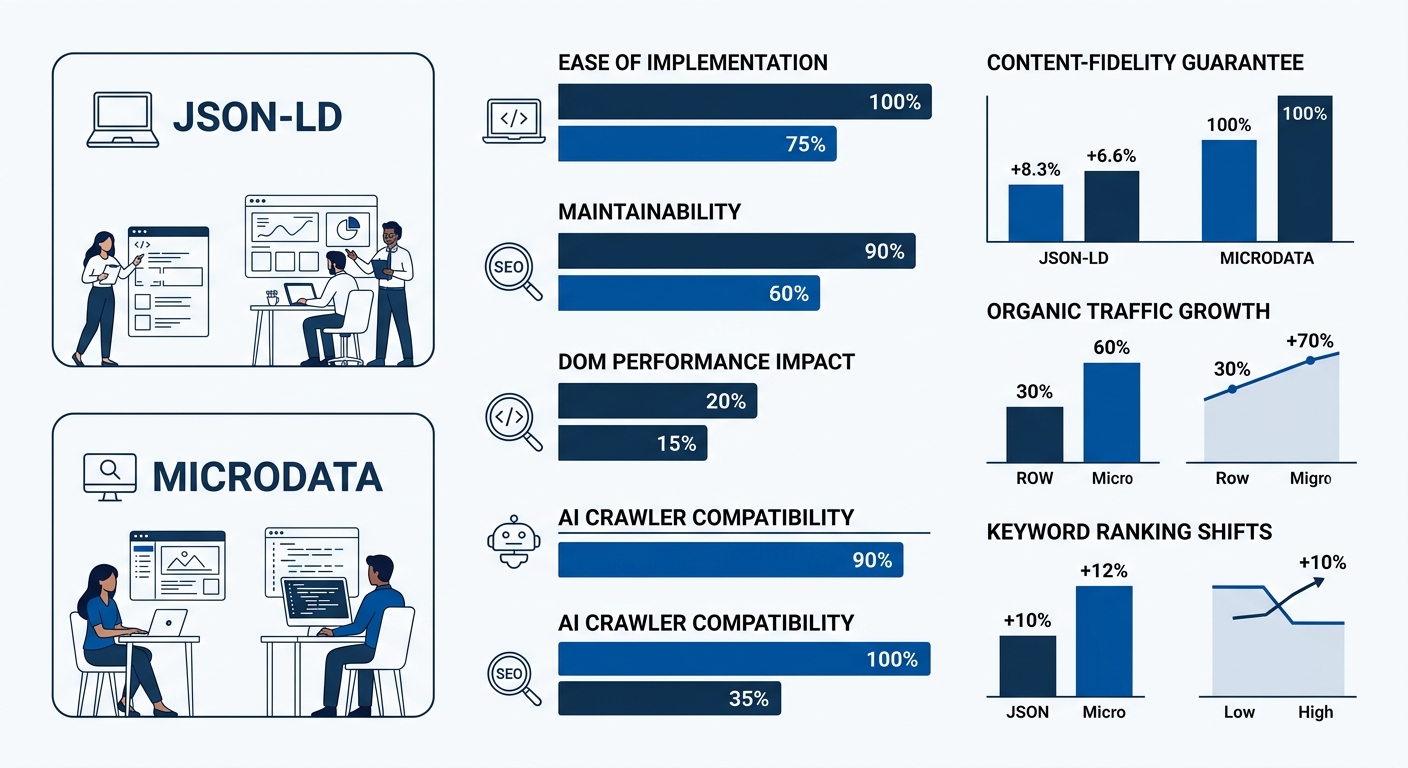
The strongest argument for Microdata is fidelity. Because the markup lives directly in the HTML elements that display content, there’s a natural guarantee that your structured data matches what users see. With JSON-LD, it’s possible — and unfortunately common — for the JSON block to drift out of sync with the page content. Google explicitly warns against this: structured data must match the visible content on the page, and dates must follow ISO 8601 format.
Microdata also makes sense for breadcrumb navigation, where the structured data maps directly to the visual breadcrumb trail in the DOM. And in legacy systems where injecting script tags is restricted by security policies or CMS limitations, Microdata remains a workable option.
But as Rishi Kumar Chawda wrote in his 2026 format comparison, “JSON-LD is still the safest default for most new projects because it is easier to implement and keep in sync.” Microdata is fine when inline HTML is the practical fit. The scenarios where it wins are real, but they’re narrowing year over year.
A Quick Note on RDFa
RDFa occupies an even smaller niche. It persists primarily in Drupal installations (which ship with RDFa support built into core), some government portals, and academic sites with existing linked-data infrastructure. For new projects, RDFa adds complexity without clear benefit over JSON-LD. Unless you’re inheriting a Drupal codebase or working within an RDF ecosystem, there’s little reason to choose it for schema.org implementation.
The Performance Angle for Philippine E-Commerce
For Philippine e-commerce sites where page speed directly affects conversion rates, the format choice carries a performance dimension worth considering.
Microdata adds markup weight to the DOM. On a product listing page with multiple schema types — Product, Offer, AggregateRating, Breadcrumb — the extra attributes can add 2 to 4 KB of inline markup scattered throughout the HTML. This increases DOM size and adds marginal parsing overhead, especially on template-heavy pages that get served thousands of times daily.
JSON-LD consolidates all structured data into a single script block. Browsers don’t render it visually. Search engine crawlers parse it separately from the DOM. The result is a cleaner HTML document that’s faster for browsers to process. If you’re already working on Core Web Vitals for your e-commerce site, switching from Microdata to JSON-LD is one of those changes that won’t show up dramatically in Lighthouse scores but removes unnecessary DOM complexity.
How to Migrate Without Breaking Rich Results
If you’re running Microdata today and want to move to JSON-LD, the process is more straightforward than most SEO migrations. Here’s the general approach:
- Audit your current markup. Use Google’s Rich Results Test on your key page templates. Document which schema types you’re currently implementing and which ones are generating rich results SEO visibility.
- Generate equivalent JSON-LD blocks. For each schema type, create the JSON-LD equivalent. Tools built into most modern CMS platforms handle this automatically. If you’re on a custom-built site, the Schema.org documentation provides examples for every type.
- Run both formats simultaneously for 2 to 4 weeks. Google can process multiple structured data formats on the same page. Keep your Microdata in place while adding the JSON-LD. Monitor Search Console for any changes in rich result eligibility.
- Remove Microdata after confirming parity. Once your JSON-LD is generating the same rich results, strip out the inline Microdata attributes. This is the step that actually cleans up your DOM and delivers the performance benefit.
Tip: Don’t mix schema types across formats on the same page after migration. If your Product schema is in JSON-LD, don’t leave your Breadcrumb schema in Microdata. Consistency makes debugging dramatically easier.
For businesses working with an agency on their overall digital marketing strategy, this migration is typically a one-time technical sprint — a few days of development work that pays dividends in maintainability for years.

Where the Data Lands Today
The microdata vs JSON-LD debate had real stakes a few years ago. In 2026, it’s effectively settled.
JSON-LD schema markup is the default for new implementations. Google recommends it. Every major CMS defaults to it. The tools that generate, test, and validate structured data are all optimized for it. And as structured data becomes increasingly important for rich results and AI-generated search answers, the format that’s easiest to maintain at scale wins by default.
Microdata isn’t dead, and it’s not going to break your site if you’re already using it. If you’re starting fresh, though, or if you’re planning any kind of schema.org implementation in 2026, JSON-LD is the clear choice. The technical advantages in maintainability, CMS compatibility, and performance are well-documented. The SEO community has largely moved past the debate, and so has Google.
The practical question for most Philippine businesses isn’t which format to choose anymore. It’s whether you’ve implemented structured data at all, whether what you have is accurate and complete, and whether it faithfully reflects what visitors actually see on the page.








