The Semantic Consolidation Trap: Why Publishing More Pages Now Kills Enterprise SEO Rankings

Every page an enterprise publishes about a topic it already covers well makes that topic harder to rank for. Search engines now consolidate similar queries to a single authoritative URL, which means additional pages on overlapping subjects split ranking signals, waste crawl budget, and actively suppress the visibility of the page that should be winning.
TL;DR: Publishing volume was a valid SEO growth lever until search engines began routing similar intents to fewer pages. Enterprises that consolidate thin or overlapping content into fewer, deeper pages consistently outperform those that keep publishing. Forty tightly interconnected pages on a topic beat 400 surface-level articles spread across adjacent themes.
Duplicate Detection Got Twice as Good, and Your Content Library Didn’t Adapt
AI-powered retrieval systems have fundamentally changed how search engines evaluate content overlap. Studies comparing traditional NLP techniques with newer generative AI approaches found that duplicate detection accuracy improved from 30% to nearly 60%, a doubling of detection effectiveness. That number matters because the threshold for what counts as “duplicate” has widened along with the accuracy. Two pages that a 2023-era algorithm would have treated as distinct (one about “SEO content strategy for ecommerce,” another about “content planning for online retail SEO”) now register as semantically identical under AI retrieval and page dedupe systems.
This is the mechanism behind the semantic consolidation trap. Enterprise sites that published aggressively through 2023 and 2024 often built content libraries with dozens of pages covering slight variations of the same topic cluster. At the time, each page could rank for its own narrow long-tail keyword. The math was simple: more pages, more keywords, more traffic.
That math broke. Search engines now treat intent overlap as redundancy. When two or three pages on your domain target queries that a semantic clustering model maps to the same intent, the search engine picks one URL, and it’s often not the one you’d choose. The others either drop from the index entirely or sit in supplemental results, contributing nothing while consuming crawl resources. If you’ve been through a crawl budget audit, you’ve seen the downstream effect: Googlebot spends its allotment on redundant pages that produce zero revenue, while the pages that should be ranking get crawled less frequently.
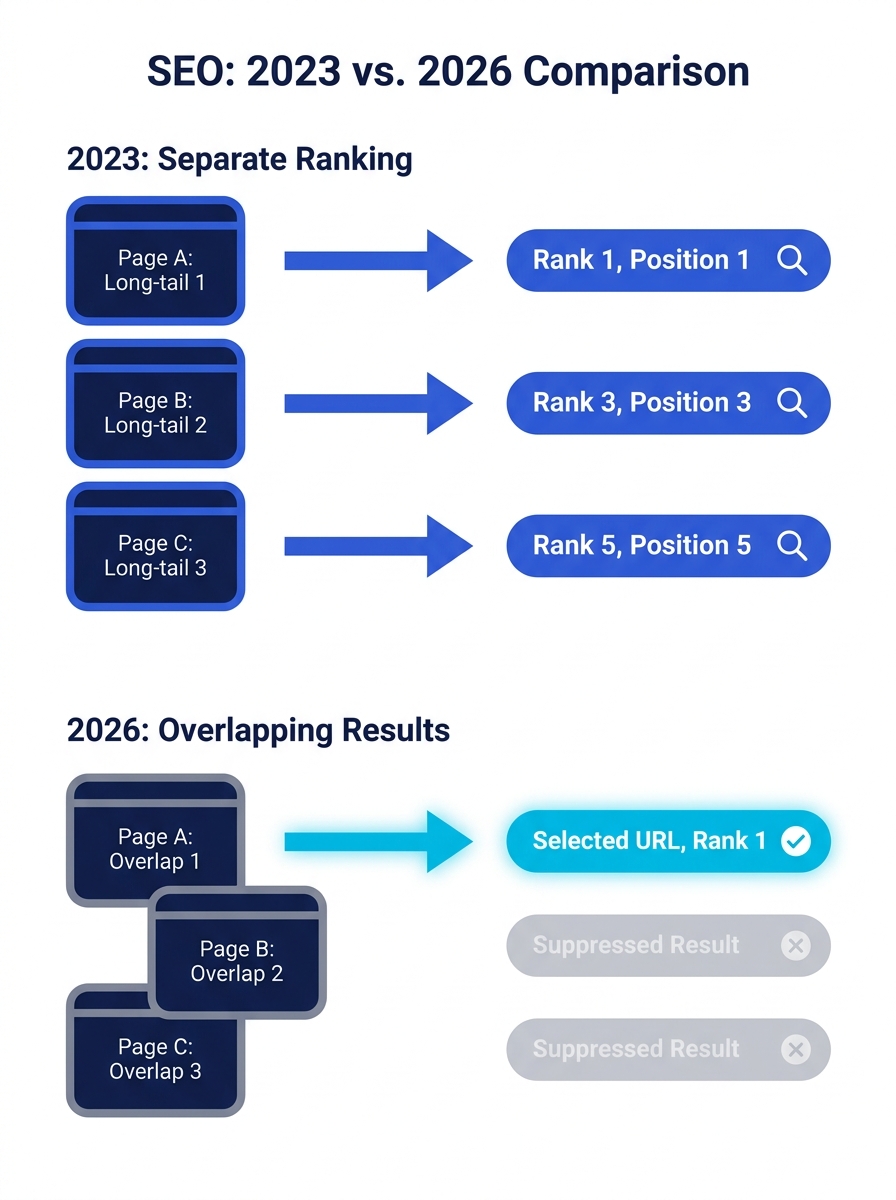
Enterprise teams that rely on tools like MarketMuse for site-wide content inventory and audit can score topical authority across hundreds of pages and flag cannibalization issues before they metastasize. But most teams don’t run these audits quarterly. They run them after the traffic decline has already hit, and by then, the information architecture bloat has been compounding for months.
The 40-Page Authority Cluster Outperforms the 400-Page Content Library
Sites with 40 tightly interconnected, substantive pieces on a defined topic consistently outperform those with 400 surface-level articles spread across adjacent themes. The relationship between content quality over quantity rankings has always been discussed in theory. The performance data at enterprise scale now confirms it.
Google’s own documentation states that low-value URLs drain crawl activity. At scale, thin or redundant content is deprioritized, meaning a significant percentage of published pages never meaningfully enter search competition. The volume play doesn’t fail quietly. It fails loudly, because every underperforming page sends negative behavioral signals (low dwell time, high pogo-sticking) that create a negative reinforcement loop affecting the domain-level quality assessment across all pages.
The editorial calendar should include consolidation sprints alongside production sprints. The question is no longer “what new pages should we publish this quarter” but “which existing pages should we consolidate, deepen, or retire.”
Search Engine Land’s architecture guidance reinforces this: dynamic URLs from filters, searches, or sort functions create endless duplicates, and the fix requires proactive planning rather than retroactive cleanup. The same logic applies to editorial content. Wherever possible, enterprises should rely on clean hierarchical URL structures and prevent unnecessary parameter-based pages from bloating the index.
The practical application for marketing leaders evaluating an enterprise SEO services engagement is to flip the standard content brief. Instead of asking “what new pages should we publish this quarter,” the question becomes “which existing pages should we consolidate, deepen, or retire.” Enterprise content consolidation SEO treats the content audit as a production activity, not a cleanup chore that gets deferred every quarter.
Semantic clustering in 2026 works differently than keyword grouping did in prior years. Tools like seoClarity’s AI Topic Map use semantic clustering to visualize content gaps and opportunities through connected topic maps, revealing where a site has over-invested in coverage breadth and under-invested in coverage depth. The pattern is consistent across enterprise verticals: too many pages competing for the same semantic space, with none of them authoritative enough to win.
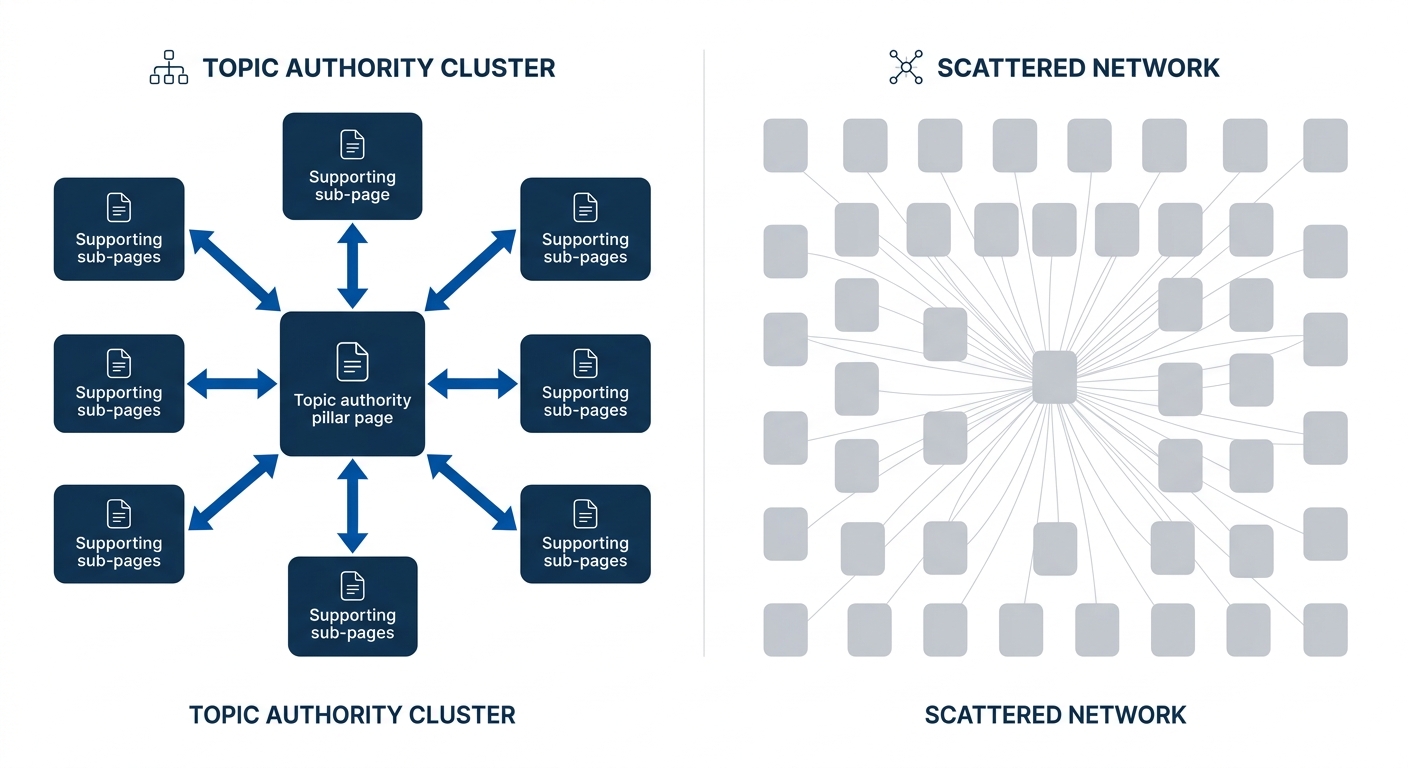
We’ve written before about how information architecture compounds organic growth when it’s tight and intentional. The inverse is also true. It compounds organic decay when it’s bloated with pages that compete against each other rather than reinforcing a shared topical position.
Every Published Page Is a Maintenance Liability That Compounds Over 18 Months
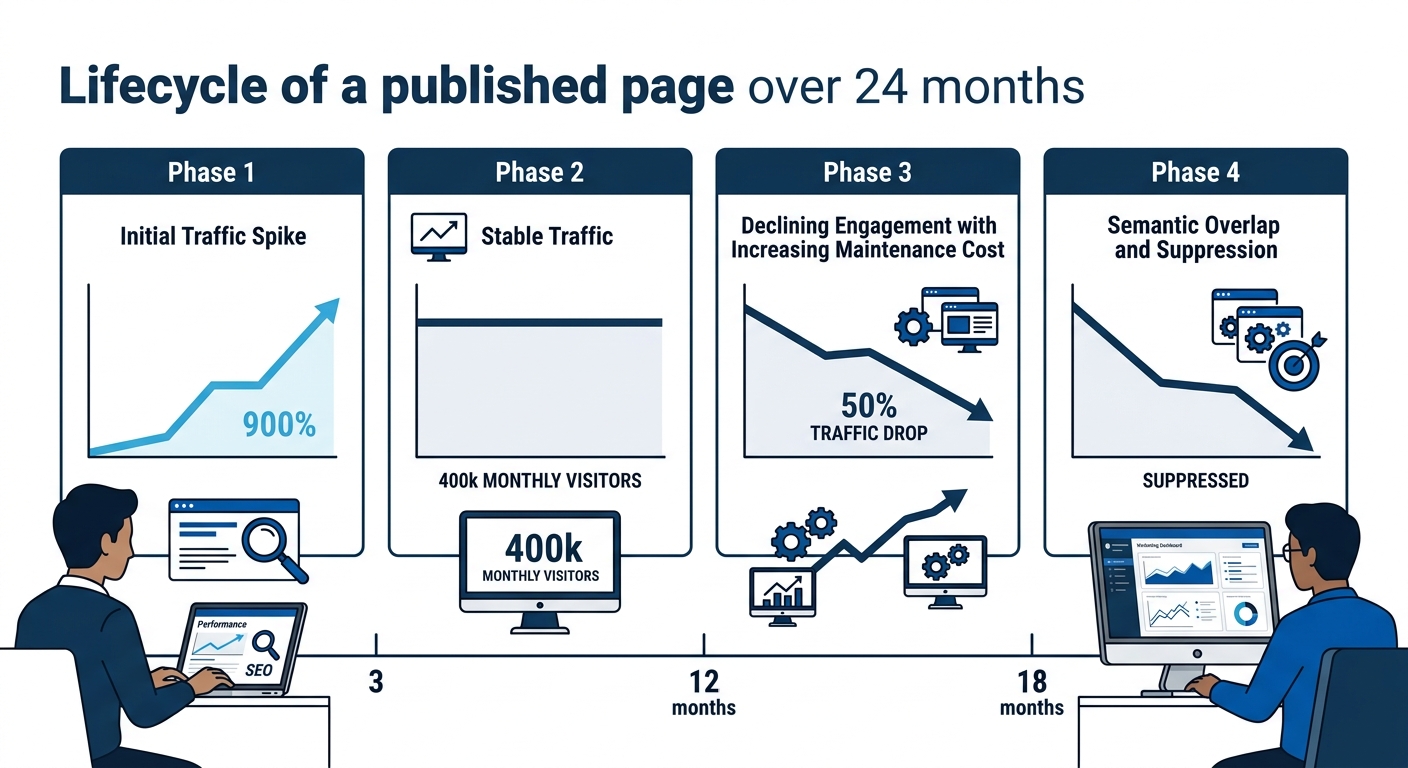
The third piece of evidence against volume-first publishing is economic, and it’s the one enterprise marketing leaders underestimate most consistently. Every page creates an ongoing maintenance obligation. At scale, large content libraries become a compounding liability that drains editorial resources. The true cost becomes visible 18 to 24 months after the initial investment, when factual accuracy degrades, internal links break, and the page’s behavioral signals deteriorate.
This is where AI retrieval and page dedupe intersects with content operations. As generative AI tools improve duplicate detection accuracy (doubled, as noted above, from 30% to 60%), the penalty for maintaining stale overlapping content increases each quarter. A page that once contributed marginal long-tail traffic now actively harms the domain’s semantic clarity, because the AI retrieval system reads it as a weaker duplicate of something you published six months later.
Gen3 Marketing captures this tension well: websites that focus solely on SEO quotas see short-term gains but struggle to maintain rankings. Their analysis also notes that “perfection is the enemy of progress” and that spending too much time on the wrong things bottlenecks strategy. The balancing act for enterprise teams is knowing which pages deserve investment and which deserve retirement. That distinction requires judgment, not a production calendar.
Warning: A content audit that only counts pages and traffic misses the critical question. The metric that matters is whether each page holds a distinct semantic position in the index, or whether it overlaps with three other pages on the same domain and dilutes all of them.
A useful internal assessment (call it the Semantic Position Test) evaluates each page against three criteria: Does this page target a query intent that no other page on the domain covers? Does it hold a measurably stronger engagement profile than competing pages on the same domain? And would merging it into a related page produce a single asset with higher topical authority than either page alone? If the answer to the third question is yes, the consolidation case is clear.
That assessment requires the kind of architecture audit that reveals hidden revenue losses buried in your information structure. The goal is to identify which pages carry real topical authority, which ones cannibalize each other, and which ones sit in the index doing nothing except consuming crawl resources and sending negative engagement signals.
Google’s passage-based ranking reinforces this at the content level. The specific value of the passage that directly answers a search query matters more than the overall quantity of content on a page. A shorter, tighter page with one genuinely authoritative passage outperforms a longer page that meanders through adjacent subtopics. And it outperforms by a wider margin now than it did two years ago, because AI retrieval systems extract and evaluate at the passage level, not the page level.
For marketing leaders already grappling with how AI agents mediate brand discovery, this reinforces a broader shift: the unit of competition in search is moving from the page to the passage, and from the passage to the entity. Publishing more pages doesn’t increase your chances of winning that competition. It fragments them across URLs that end up fighting each other.
The Claim, Revisited
The contrarian position here holds up under three separate lines of evidence. AI duplicate detection has doubled in accuracy, meaning overlapping pages get caught and penalized faster. Query consolidation routes similar intents to fewer URLs, meaning additional pages on the same topic split authority rather than building it. And every page carries a maintenance cost that compounds over 18 to 24 months, eventually degrading the domain’s overall quality signals.
The enterprise content consolidation SEO playbook that follows from this evidence looks nothing like the content calendars most marketing teams ran through 2024. It prioritizes depth within defined topic clusters, treats consolidation as a production activity equal in importance to new content creation, and applies semantic clustering in 2026 to identify which pages deserve investment and which deserve merging or retirement. Marketing leaders who want their site architecture to recover lost organic revenue are better served by an honest audit of what already exists than by another quarter of publishing into an already crowded index.
The information architecture bloat problem won’t resolve on its own. Google’s systems are getting better at detecting it, AI retrieval systems are getting better at ignoring it, and the editorial cost of maintaining it grows every quarter. The enterprises that recognized this shift early and began consolidating have already seen the organic visibility lift. For those still running volume-first content strategies, the correction starts with accepting that the next 40 pages you don’t publish may do more for your rankings than the last 400 you did.








